
Prometheus
Prometheus는 오픈소스 시스템 모니터링, 경고 툴킷이다. 2012년 SoundCloud에서 개발했으며 현재는 독립적인 오픈소스 프로젝트로서 여러 회사들에 의해 관리되고 있다. 2016년 쿠버네티스 다음으로 Cloud Native Computing Foundation에 합류했다.
Prometheus는 모든 데이터를 로컬에 저장한다. 그 자체가 시계열 데이터베이스면서 동시에 모니터링 도구이다.
Main features
- 메트릭 이름과 키/값쌍으로 구분되는 시계열 데이터가 포함된 다차원 데이터 모델
- 위와 같은 데이터 모델을 활용하는 유연한 쿼리 언어, PromQL
- HTTP에서 동작하는 Pull 모델을 통한 시계열 수집
- 중개 게이트웨이를 통한 시계열 Push 지원
- 분산 스토리지에 대한 의존성 없음
- 서비스 디스커버리 또는 정적인 설정을 통해 타겟 발견
- 다양한 모드의 그래프 및 대시보드 지원
Components
- 시계열 데이터를 수집하고 저장하는 메인 prometheus server
- 응용프로그램 코드를 계측하기 위한 client library
- 짧은 작업을 지원하는 push gateway
- HAProxy, StatsD, Graphite 등의 특수목적 서비스를 위한 exporter
- 경보를 처리하는 alertmanager
대부분의 컴포넌트는 Go 언어로 작성되어있으며 쉽게 빌드하고 정적 바이너리로 배포할 수 있다.
Architecture
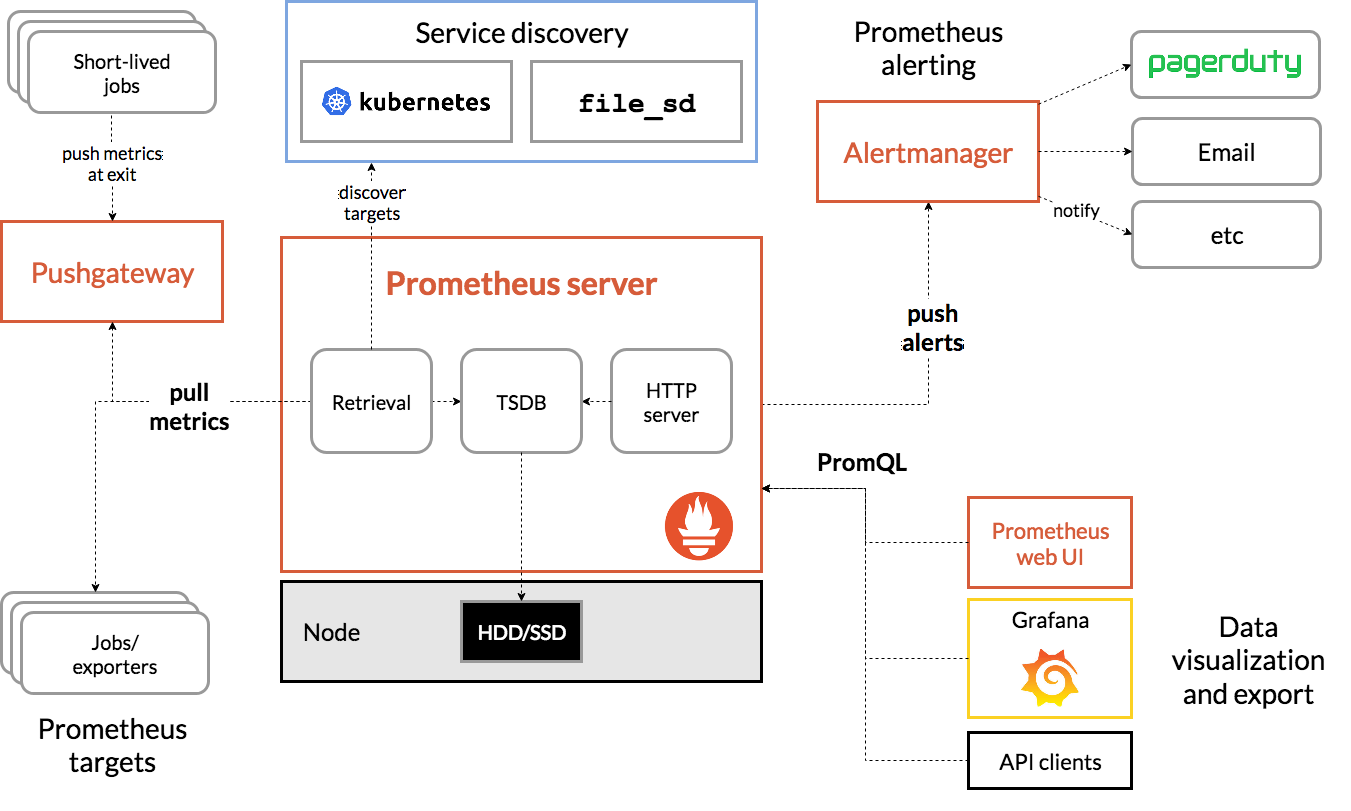
Concepts
Data model
Prometheus는 근본적으로 모든 데이터를 시계열 데이터(동일한 메트릭과 동일한 label이 지정된 차원 세트가 포함된 타임스탬프 값 스트림)로 저장한다.
모든 시계열 데이터는 metric name과 label이라 불리는 선택적인 키/값쌍으로 고유하게 식별된다.
metric name은 측정되는 시스템의 일반적인 기능을 지정합니다.
[a-zA-Z_:][a-zA-Z0-9_:]* 정규표현식에 맞는 문자열로 지정해야한다.
콜론(:)은 유저가 정의한 레코딩 규칙을 위해 예약되어있으므로 exporter나 direct instrumentation에서 사용되면 안된다.
label은 동일한 메트릭 내에서 데이터의 종류를 구분하기 위한 식별자이다.
동일한 metric name 내에 서로 다른 label을 사용하는 여러 데이터가 존재할 수 있으며 label은 변경되면 새로운 시계열 데이터를 생성한다.
[a-zA-Z_][a-zA-Z0-9_]* 정규표현식에 맞는 문자열로 지정한다.
Metric types
Prometheus 클라이언트 라이브러리는 4가지 유형의 코어 메트릭 타입을 제공한다.
Counter
카운터는 단순히 증가만 가능한 단일 숫자 타입이며 증가하거나 0으로 리셋되는 것만이 가능하다. 에러 발생 수나 리퀘스트 수 등을 나타내기 위해 사용될 수 있으며 현재 동작하는 프로세스 수 같이 값이 내려갈 수 있는 지표에는 사용해서는 안된다.
Gauge
게이지는 단일 숫자값을 표현하기 위해 사용된다. 카운터와 다른 점은 게이지는 숫자값을 내릴 수 있다는 것이다.
Histogram
특정 기간동안 측정된 값을 표현할때 사용하며 모든 메트릭 데이터의 합계를 제공한다.
Summary
히스토그램과 유사하게 수치를 샘플링하며 측정된 값의 합, 측정 횟수, 사분위수 값이 데이터에 포함되어 있다.
Jobs and Instance
Prometheus는 보통 단일 프로세스와 같이 수집 가능한 엔드포인트를 instance라 부르며 동일한 목적을 가진 instance가 안정성, 스케일링 등을 위해 묶여있는 집합을 job이라고 부른다.
Prometheus가 타겟의 데이터를 수집할 때 자동으로 몇가지 label을 시계열 데이터에 붙인다.
- job: 해당 타겟이 속한 잡 이름
- instance: 타겟 URL의
<host>:<port>부분
만약 이 label들이 이미 수집된 데이터에 포함되어 있을 경우 honor_labels 설정값에 따라 해당 label을 그대로 두거나 수집된 데이터의 label 이름을 변경한다.
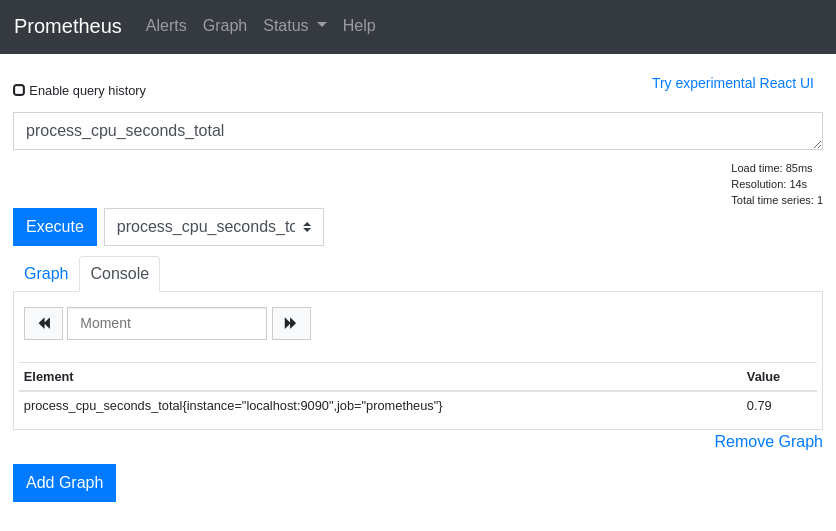
Installation
다운로드 페이지에서 Prometheus를 다운로드 받는다.
cd /usr/local
wget https://github.com/prometheus/prometheus/releases/download/v2.18.1/prometheus-2.18.1.linux-amd64.tar.gz
tar xvfz prometheus-*.tar.gz
rm prometheus-2.18.1.linux-amd64.tar.gz
ln -s prometheus-2.18.1.linux-amd64/ prometheus
cd prometheus
./prometheus --config.file=prometheus.yml
Prometheus는 HTTP를 통해 지정된 타겟의 메트릭 정보를 수집하며 Prometheus 자체도 동일한 방식으로 데이터를 노출하므로 자기자신에 대한 메트릭을 수집하고 모니터링 할 수 있다.
Prometheus는 기본적으로 9090포트로 자신을 노출한다.
localhost:9090로 접근하여 상태 페이지를 확인할 수 있으며 localhost:9090/metrics 엔드포인트 Prometheus가 제공하는 메트릭 정보를 확인할 수 있다.
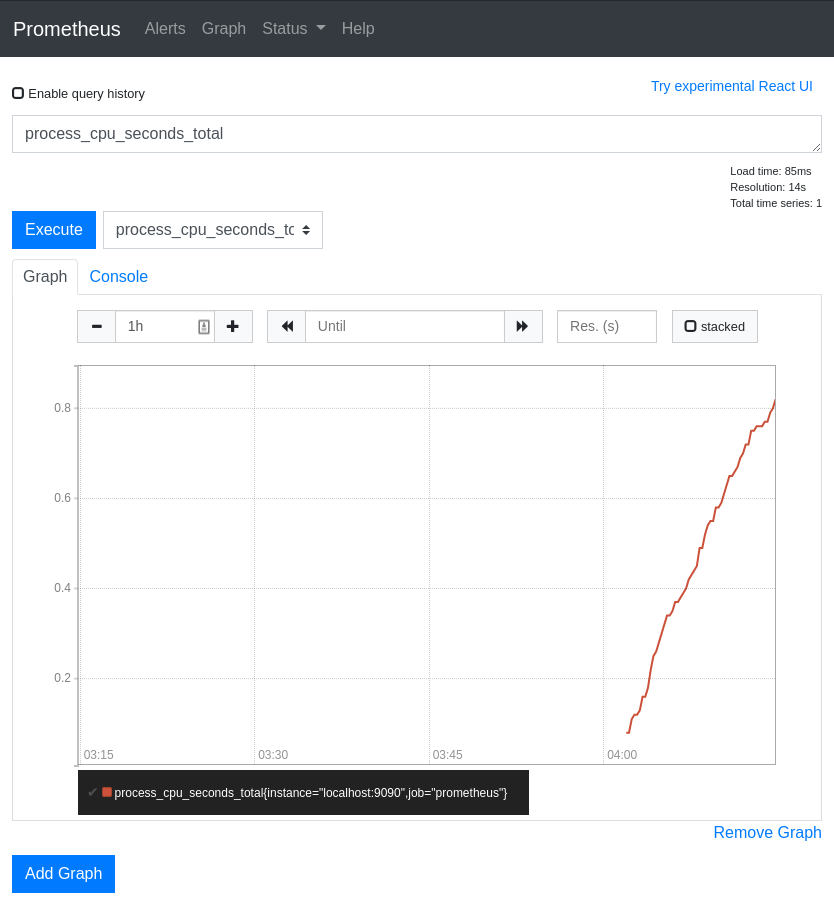

천개가 넘는 시계열 데이터의 집합을 매번 임시로 쿼리하는 것은 느릴 수 있다. Prometheus는 사전 구성된 규칙을 통해 수집된 데이터를 아예 새로운 지속적인 시계열 데이터로 표현할 수 있다.
# prometheus-recording.yml
groups:
- name: example
rules:
- record: job_service:rpc_durations_seconds_count:avg_rate5m
expr: avg(rate(rpc_durations_seconds_count[5m])) by (job, service)
# prometheus.yml
...
rule_files:
- "prometheus-recording.yml"
...
이제 job_service:rpc_durations_seconds_count:avg_rate5m 를 쿼리할 수 있다.
Configuration
Prometheus는 커맨드라인 옵션이나 설정파일로 설정할 수 있다. 커맨드라인 옵션은 변하지 않는 시스템 파라미터를 설정하기위해 사용되며 설정파일은 룰 파일을 포함해 데이터 수집과 인스턴스들에 대해 설정하기위해 사용된다.
설정파일은 yaml 포맷으로 작성하며 실행중에도 리로드할 수 있다.
새로운 설정파일이 제대로 작성되지 않았다면 변경사항은 반영되지 않는다.
SIGHUP 시그널을 통해 설정을 리로드할 수 있으며 --web.enable-lifecycle 옵션을 설정했다면 /-/reload 엔드포인트에 HTTP POST 리퀘스트를 보내는 것으로도 리로드 할 수 있다.
scrape_config에서는 타겟과 어떻게 데이터를 수집할지에 대해 지정한다.
타겟은 static_configs 를 통해 정적으로 설정하거나 서비스 디스커버리를 통해 동적으로 발견하도록 설정할 수도 있다.
Prometheus는 AWS, Azure 등 클라우드 서비스 벤더나 OpenShift 같은 쿠버네티스 클러스터, Consul, DNS 등을 통해 동적으로 서비스 디스커버리를 할 수 있다.
Global
Prometheus에는 scrape_interval과 evaluation_interval이라는 두가지 중요한 설정이 있다.
scrape_interval은 메트릭을 수집하는 빈도이며 evaluation_interval은 경고 상태를 확인하고 변경하는 빈도이다.
경고는 evaluation cycle 때만 상태가 변경된다.
Configuring rules
Prometheus는 recording rule과 alerting rule이라는 두 가지 타입의 룰을 지원한다. 룰을 설정하기 위해서는 룰 설정파일을 만든 뒤 Prometheus 설정에서 rule_files 필드에 해당 룰 파일들을 추가하면 된다.
룰 파일은 promtool이라는 커맨드라인 유틸리티를 통해 Prometheus 서버를 설치하거나 실행하지 않아도 문법 검사를 할 수 있다.
Recording rule
recording rule을 설정하면 자주 사용하거나 계산 비용이 많이 드는 표현식을 사전에 미리 새 시계열 데이터로 저장해둘 수 있다. 쿼리를 사전에 계산하므로 결과를 더 빠르게 확인할 수 있다. 주로 대시보드에 유용하게 사용할 수 있다.
Alerting rule
alerting rule은 Prometheus 표현식에 기반하여 외부 서비스로 알림을 보내기위해 사용된다. alerting rule은 recording rule과 동일하게 설정한다.
표현식의 결과가 하나 이상일 경우 경고가 활성화된다.
경고가 활성화 되면 해당 alerting rule이 inactive 상태에서 firing 상태로 전환된다.
for 문을 사용하면 경고가 발생하는 것을 지연시킬 수 있다.
inactive 상태의 경고가 firing 상태로 전환되기전 for 문을 통해 설정한 시간만큼 pending 상태가 되며 대기가 끝난뒤 다음 번 evaluation cycle에도 경고가 활성화되어있다면 firing 상태에 진입한다.
labels 문에는 경고에 대한 추가적인 label을 지정할 수 있다.
annotations 문에는 설명이나 runbook 링크 같이 더 긴 추가 정보를 라벨링하기 위해 사용된다.
labels와 annotations는 템플릿화할 수 있다.
Prometheus의 alerting rule은 현재 발생한 문제를 확인하기에는 좋지만 아주 본격적인 알림 솔루션은 아니다. 요약 알림 발생 빈도를 조절하거나 아예 침묵시키기 위해 다른 레이어가 필요하며 Prometheus의 생태계에서는 Alertmanager가 이러한 역할을 수행한다.
Alertmanager
Alertmanager는 Promethues 서버와 같은 클라이언트로부터 경고를 수신받아 처리한다.
Alertmanager는 중복제거 기능(deduplicating), 유사한 특성의 경고를 하나의 알림으로 분류하는 기능(grouping)이나 이메일, Slack 같은 적절한 리시버로 경고를 라우팅하는 기능을 가지고 있으며 경고 발생을 잠시 중단(silences)하거나 특정 경고 발생사 다른 특정 경고에 대한 알림을 보내지 않는 기능(inhibition)도 가지고 있다.
Alertmanager는 고가용성을 위해 클러스터를 생성할 수 있다. Prometheus와 Alertmanager 사이의 로드밸런싱보다 Prometheus가 모든 Alertmanager를 바라보도록 하는 것이 중요하다.
Installation
다운로드 페이지에서 Alertmanager를 다운로드 받는다.
cd /usr/local
wget https://github.com/prometheus/alertmanager/releases/download/v0.20.0/alertmanager-0.20.0.linux-amd64.tar.gz
tar xvfz alertmanager-0.20.0.linux-amd64.tar.gz
rm alertmanager-0.20.0.linux-amd64.tar.gz
ln -s alertmanager-0.20.0.linux-amd64/ alertmanager
cd alertmanager
./alertmanager --config.file=alertmanager.yml
Configuration
receivers
수신받을 채널에 대한 구체적인 정보를 설정한다. 각 채널별로 필요로하는 정보들이 다르며 매뉴얼을 확인하여 필요한 정보를 입력한다.
route
어떤 경고를 어느 receiver에게 보낼지 설정한다. label에 따라 그룹핑하고 어떤 label에 어떤 값이 있는지에 따라 발송할 receiver를 지정할 수 있다.
route 설정 중에는 group_wait와 group_interval, repeat_interval 문이 있다.
group_wait는 알림을 보내기 전 동일한 그룹의 다른 경고를 기다리기 위한 시간이다.
경고가 발생하면 group_wait에 설정한 시간만큼 알림을 버퍼링하다가 해당 그룹과 동일한 경고가 발생할 경우 한번에 묶어서 발송한다.
group_wait만큼 기다린 뒤 알림을 발송하고 그 이후에 추가로 동일한 그룹의 경고가 발생하면 group_interval만큼 기다린 뒤 알림을 발송한다.
알림이 전송된 후 상태가 변경되지 않는다면 repeat_interval만큼 대기한 뒤 다시 알림을 전송한다.
참고
Prometheus Documents
곰팡이 먼지연구소 :: Prometheus 를 알아보자
Prometheus 2편. PromQL 사용하기, k8s에서 Meta Label과 relabel을 활용한 기본 라벨 설정, 그 외의 이야기
whats-the-difference-between-group_interval-group_wait-and-repeat_interval
prometheus-understanding-the-delays-on-alerting