
Gluster는 자동으로 장애조치를 할 수 있는 분산형 파일시스템이다. 모든 작업은 중앙 메타데이터 서버 없이 수행된다. 대부분의 하드웨어에서 쉽게 NAS를 구성할 수 있다. 처음부터 원하는만큼 서버를 추가할 수 있고 클러스터가 설치된 이후에도 쉽게 스케일아웃이 가능하다.
자동으로 장애복구를 하도록 구성할 수 있으며 이 과정에서 어떠한 수동조작도 필요로하지 않는다. 장애가 발생한 서버를 다시 시작했을 때에도 별도의 수동조작을 필요로 하지 않으며 그저 기다리기만 하면 된다. 복구된 서버가 데이터를 동기화하는 동안은 기존 노드들이 파일을 서비스한다.
Archithecture
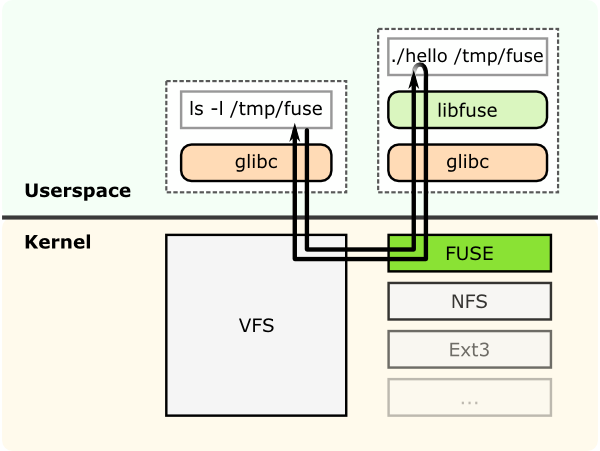
FUSE
GlusterFS는 사용자 공간 파일시스템이다. GlusterFS 개발자는 Linux 커널 모듈을 필요로 하지 않도록 이러한 방법을 선택했다. 그렇기 때문에 커널 VFS와 상호작용하기 위해 FUSE(File System in Userspace)를 사용한다.
FUSE는 커널 VFS와 권한이 없는 사용자 공간 애플리케이션 사이의 상호작용을 위한 커널 모듈이다. FUSE는 사용자공간에서 접근할수 있는 API를 제공한다. API는 다양한 언어 바인딩을 제공하므로 여러 언어를 통해 파일 시스템을 만들 수 있다.
Translator
Translator는 유저의 요청을 스토리지를 위한 요청으로 변경한다. Translator는 요청의 타입을 다른 타입으로 변경하거나 위치, 플래그를 변경할 수 있으며 데이터 또한 변경(encryption)할 수 있다. Translator는 요청을 가로채거나 차단(access control)할 수 있으며 새 요청을 생성(pre-fetch)할 수도 있다.
GlusterFS
GlusterFS가 서버에 설치되면 gluster management daemon인 glusterd 데몬이 생성되며 해당 데몬을 통해 trusted storage pool에 속한 peer의 brick들을 조합하여 volume을 생성한다.
volume이 생성되면 brick마다 glusterfsd 프로세스가 실행되며 이와 함께 volfile이라 불리는 설정 파일이 각 brick마다 생성된다. 이 설정파일에는 각 brick에 대한 새부적인 정보가 들어있다. volfile은 클라이언트 프로세스가 필요로 한다.
클라이언트에서 GlusterFS volume을 마운트하면 클라이언트 glusterfs 프로세스는 서버의 glusterd 프로세스와 통신하게 된다. glusterd는 클라이언트에게 volfile을 전달한다. 클라이언트는 volfile을 통해 volume에 속한 각 brick의 정보를 알게 되고 brick의 glusterfsd와 직접 통신할 수 있게 된다.
Concept
Gluster는 실제 파일시스템은 아니다. Gluster는 여러 파일시스템들을 하나의 큰 덩어리로 연결하여 여러 서버에 배포된 파일을 동시에 읽거나 쓸 수 있게 한다. XFS 파일시스템을 권장하지만 다른 파일시스템 또한 가능하긴 하다. XFS가 아닐 경우 주로 EXT4가 사용된다.
Glusterd Service
glusterd 서비스는 탄력적인 볼륨 관리 서비스로서 glusterfs 프로세스들을 감시하고 볼륨 추가나 제거와 같은 작업을 동적으로 수행할 수 있도록 조정한다.
Trusted Storage Pool
trusted storage pool은 gluster 클러스터에 연결된 모든 호스트를 의미한다. glusterfs 볼륨을 설정하기 전에 trusted storage pool을 구성해야한다. trusted storage pool로 구성된 서버들은 볼륨 생성에 사용할 brick을 제공한다.
Brick
brick은 gluster 스토리지에 사용하는 모든 장치(파일시스템)을 의미한다.
Export
export는 서버에서 brick이 마운트되어있는 경로를 의미한다.
Volume
glusterfs에서 volume이란 brick들의 논리적인 집합을 의미한다. volume을 생성한 뒤 해당 volume을 마운트해서 사용하기 위해서는 꼭 volume을 start해야한다.
Volume Types
Distributed
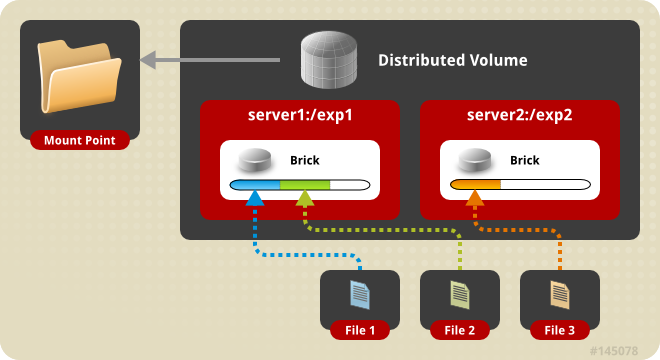
distributed volume은 파일을 각 brick들에 무작위로 분산하여 저장한다. 중요하지 않은 파일들을 저장할 때 용량을 최대한 확보하기 위해서 사용할 수 있다.
전송 유형을 지정하지 않으면 TCP가 기본값으로 사용된다.
필요한 경우 auth.allow 또는 auth.reject와 같은 추가 옵션을 설정할수도 있다.
Replicated
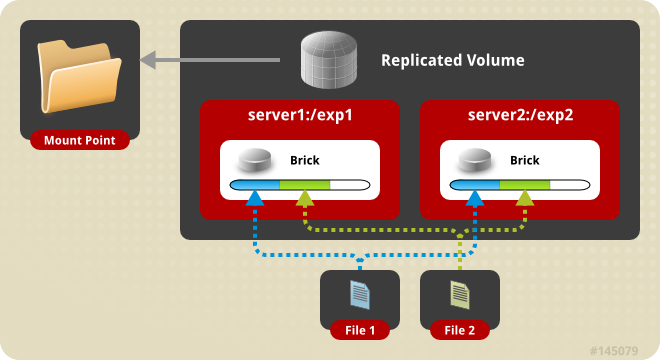
replicated volume은 파을 각 brick들에 동일하게 저장한다. 고가용성을 보장하기 위해 사용한다.
brick수는 복제된 volume의 복제본 수와 같아야한다.
서버 및 디스크 장애로부터 보호하려면 volume의 brick을 다른 서버에서 가져오는 것이 좋다.
동일한 peer에서 복제 세트의 둘 이상의 brick이 있는 경우 glusterfs는 복제 volume을 생성하지 못한다.
이 경우 volume을 생성하기 위해서는 force 옵션을 사용해야한다.
Distributed Replicated
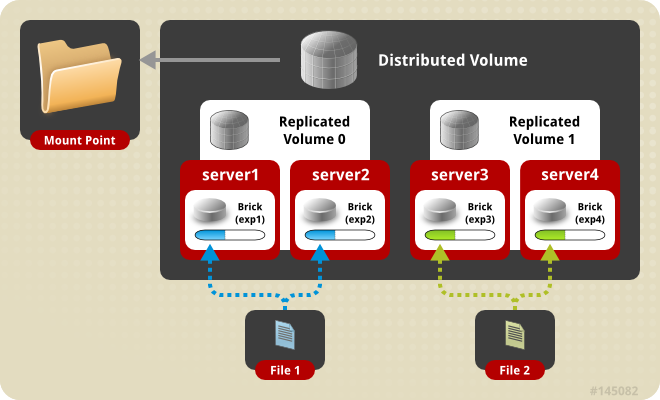
distributed replicated volume은 복수의 replicated volume에 분산하여 파일을 저장한다. 고가용성을 보장하면서 스토리지를 스케일아웃 하기 위해 사용한다. brick 수는 복제 volume에 대한 복제 수의 배수여야한다.
Dispersed
erasure coding을 사용하여 파일을 분산한다. RAID5, 6의 parity 방식과 유사하다.
Distributed Dispersed
distributed replicated volume과 동일하지만 데이터를 복제하는 대신 erasure coding을 사용한다.
Installation
Setup Firewall
신뢰할 수 있는 환경에서 방화벽 없이 사용하는 것이 권장된다. 만약 방화벽을 사용해야할 경우 Setting Up Clients 매뉴얼을 참고하여 방화벽을 설정해야한다.
firewall-cmd --add-service=glusterfs --permanent
firewall-cmd --reload
-A INPUT -m state --state NEW -m tcp -p tcp --dport 24007:24008 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 49152:49156 -j ACCEPT
Setup Partition
brick으로 사용할 파티션을 마운트하고 XFS 파일시스템으로 포맷한다. 루트 파티션에서 brick을 설정할 수도 있지만 권장하지 않는다.
# 마운트 포지션 생성
mkdir -p /data/glusterfs/gv01/brick01
# 파티션을 XFS 파일시스템으로 포맷한다.
mkfs.xfs /dev/vdb1
# 각 파티션의 UUID를 확인한다.
blkid
**#** blkid로 확인한 파티션의 UUID를 사용하여 마운트한다.
# UUID=UUID /data/glusterfs/gv01/brick01 xfs defaults 1 2
vim /etc/fstab
mount -a
mkdir /data/glusterfs/gv01/brick01/brick
Install GlusterFS
gluster 클러스터를 구성할 모든 서버에 gluster-server 패키지를 설치하고 실행한다.
dnf install centos-release-gluster -y
dnf --enablerepo=PowerTools install glusterfs-server -y
systemctl enable --now glusterd
Configure Pool
DNS나 /etc/hosts 파일을 통해 각 서버들이 hostname으로 서로를 식별할 수 있도록 설정한다.
cat << EOF >> /etc/hosts
192.168.0.2 test-gluster01
192.168.0.3 test-gluster02
192.168.0.4 test-gluster03
EOF
한 대의 서버에서 다른 서버들을 상대로 클러스터를 구축한다.
gluster peer probe test-gluster02
gluster peer probe test-gluster03
Setup Volume
각 서버의 brick을 volume으로 엮는다.
gluster volume create gv01 replica 2 \
test-gluster{1..2}:/data/glusterfs/gv01/brick01/brick
gluster volume start gv01
Setup Client
여러 방법을 통해 gluster volume에 접근할 수 있다. Linux 클라이언트에서는 성능과 안정성, 장애조치를 위해 Gluster Native Client를 사용하는 것이 권장되며 NFS v3 또는 NFS-Ganesha를 통해 NFS v4로 연결할 수도 있다.
Gluster Native Client
gluster native client는 사용자공간에서 FUSE 베이스로 동작하기 때문에 FUSE 커널 모듈이 설치되고 로드되어있어야한다.
우선 필요한 패키지들을 설치한다.
sudo yum -y install openssh-server wget fuse fuse-libs openib libibverbs glusterfs-client-xlators
/etc/fstab 파일에 마운트 정보를 입력한다.
HOSTNAME-OR-IPADDRESS:/VOLNAME MOUNTDIR glusterfs defaults,_netdev 0 0
마운트 정보에서 사용되는 호스트네임은 volfile을 가져오기 위해서만 사용되며 클라이언트는 volfile에 명시된 각 서버들과 직접 통신한다.
Administration
Expand a Volume
distributed volume의 경우 아래와 같이 volume을 확장할 수 있다.
gluster volume add-brick vol01 server:/brick
만약 distributed replicated volume 일 경우 용량 확장을 위해서는 replica의 배수로 brick을 추가해야한다.
gluster volume create vol01 replica 2 server1:/brick server2:/brick
gluster volume add-brick vol01 server3:/brick server4:/brick
Shrinking Volumes
brick을 제거하여 distributed volume에서 용량을 줄일 수 있다.
distributed replcated volume과 distributed dispersed volume은 replica와 stripe의 배수만큼씩 줄일 수 있다.
remove-brick 커맨드 사용시 삭제될 brick에 있는 데이터를 이전하기위해 자동으로 rebalance 작업을 진행한다.
remove brick 작업을 시작한다.
gluster volume remove-brick vol01 server2:/brick start
remove brick 작업의 상태를 확인한다.
gluster volume remove-brick vol01 server2:/brick status
remove brick 작업의 상태가 completed가 되면 commit 작업을 진행한다.
gluster volume remove-brick vol01 server2:/brick commit
Change Replica Count
replicated volume을 확장하거나 줄일 경우 replica 옵션을 사용한다.
gluster volume create vol01 replica 2 server1:/brick server2:/brick
gluster volume add-brick vol01 replica 3 server3:/brick
gluster volume remove-brick vol01 replica 2 server3:/brick start
gluster volume remove-brick vol01 replica 2 server3:/brick commit
Cleanup Brick
volume에서 brick을 제거하고 다시 해당 디렉토리를 volume으로 활용하려고 하면 이미 volume이 사용중이라 해당 brick을 사용할 수 없다는 경고가 발생한다.
이는 의도된 동작으로 brick 디렉토리를 완전히 삭제하고 다시 생성하거나 아래 커맨드를 통해 디렉토리에 설정된 속성을 제거하고 .glusterfs 디렉토리를 제거해야한다.
setfattr -x trusted.glusterfs.volume-id $brick_path
setfattr -x trusted.gfid $brick_path
rm -rf $brick_path/.glusterfs
Split Brain
두 개 이상의 복제된 파일이 서로 다른 경우를 split brain이라 한다. split brain이 발생했다는 것은 동일한 파일의 복제본을 가지고있는 brick간 또는 메타데이터간에 불일치가 있으며 이를 복구할만한 충분한 정보가 부족함을 의미한다.
대표적으로 네트워크 단절로 인해 클라이언트와 brick들 간에 연결이 끊기거나 gluster brick 프로세스들이 내려가거나 에러를 반환하는 경우에 발생한다.
만약 replica 2 volume을 사용할경우 가용성을 잃지않고 split brain을 예방할 수 없으며 replica 3 volume을 사용하거나 arbiter volume을 사용하여 split brain을 예방할 수 있다.
참고
Gluster Documents
CentOS SIG - Gluster Quickstart
GlusterFS Path or a Prefix of It is Already Part of a Volume/